
Heterogeneous Computing Part #2 : Processing Paradigms


In the previous post (Heterogeneous Computing from the First Principle : Part #1), we explored the basics and definition of heterogeneous computing.
Today, we will dive deeper into the different processing paradigms that power these systems and identify their performance and efficiency.
A Historical Overview of Computer Architectures and Processing Paradigms
By offloading specialized tasks to the most appropriate processing units, heterogeneous systems can outperform traditional homogeneous systems based on general-purpose CPUs. This paradigm is particularly important in areas such as mobile computing, where optimizing performance and saving energy is critical. Before diving into the field of heterogeneous computing, it is important to understand how we got here by looking at the evolution of computer architectures and processing paradigms.
1 . The Beginning: Single Instruction, Single Data (SISD)
In the early days of computing, the first processors followed a very simple architecture known as SISD (Single Instruction, Single Data). This means that a single processor would execute one instruction at a time on a single piece of data. This type of processors are characterized by sequential processing and low computational power.
2 . The Advent of Pipelining
In Pipelining (also called temporal parallelism or pseudo parallelism) a single task (instruction) is broken into different stages. Multiple instructions can be spread across the stages, each stage take a percentage from total time of the cycle, we can get ideal pipeline when all stages has identical time and take all time of the clock cycle.
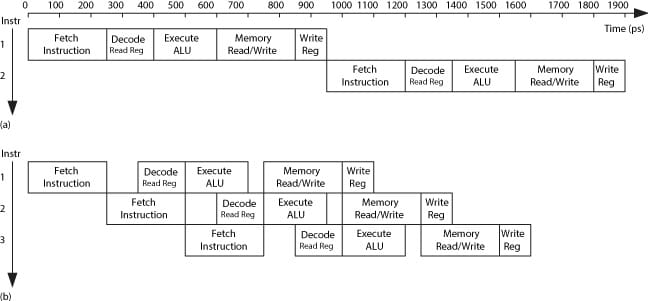
Figure (1) show dierent between a single cycle processor and pipelined processor(staged). Figure (2) show the architecture view of Single-cycle and Pipelined processor, the pipelined processor need to save the state of each stage, so we have a Register(Pipeline register) between each two stages.
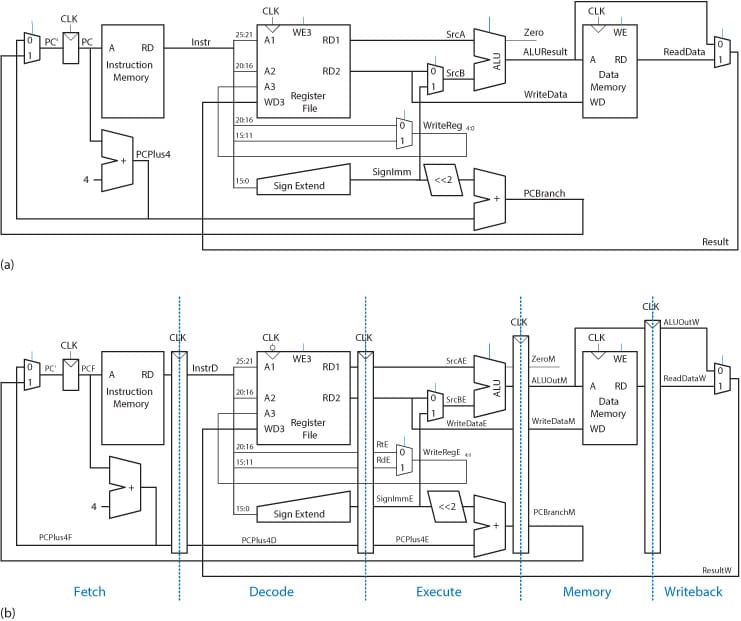
The pipeline can improve the throughput, we can execute five instructions simultaneously, and the latency of each instruction is still same(1 Cycle Per Instruction CPI). The pipeline in this example is almost five times faster than a single-cycle processor, but not ideal due to the overhead between each stage. Stages don't have the same time, so won't be faster as high as we'd like. Another problem with pipelined processors is data and control dependencies between instructions, we need to figure out how to find, plan and manage dependencies before the execution stage, so we can execute independent instructions in a full pipeline or even in parallel (superscalar).
3. Superscalar Architecture
Building on the success of pipelining. Superscalar processors can execute multiple instructions in a single clock cycle by using multiple execution units. This means that superscalar processors increase the speed of general-purpose computers, while pipelines only allow one instruction per phase.
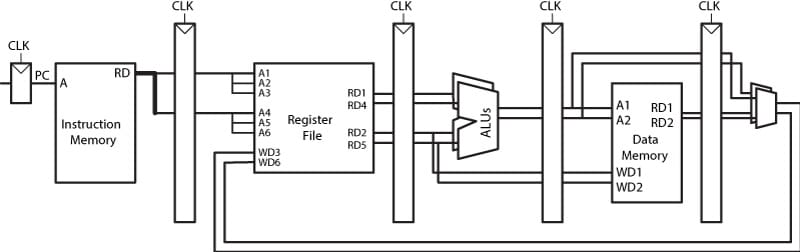
Figure 3 shows an example of a two-way superscalar processor. This processor that can executes two instructions simultaneously per cycle. However, as we saw with pipelined processors, it is difficult to execute many instructions at the same time due to the dependencies between instructions. Out-of-order processors excel when dealing with dependencies.
4. Out-of-order Execution (OOE)
As we all know, when writing programs, processors execute instructions in sequential mode. In out-of-order, instructions can be executed in a dierent order than the programmer wrote, and the choice of order is dynamic.
Out-of-order uses several techniques to deal with instructions hazard(Dependency), one of them is Register Renaming.
Conclusion
In the next post, we will take a deeper look at data-level parallelism. We will examine the key benefits and differences between Homogeneous and Heterogeneous systems. Additionally, we will explore innovative approaches used in In-Memory/Near-Memory computing. These concepts illuminate cutting-edge technologies that are driving today’s computing landscape and shaping the future of technology. Stay tuned for more insights!
References
- David Money Harris and Sarah L. Harris. "Digital Design and Computer Architecture". Second Edition 2013.
- Intel. Intel Processor Graphics: Architecture & Programming. 2015. (visited 04/07/2022)
- Mohamed Zahran. "Heterogeneous Computing: Hardware and Software Perspectives". Association for Computing Machinery, 2019.
- Wikipedia. Register Renaming. (visited on 04/10/2022).